Transform your org with innovative, secure, cloud-native AI solutions today.. CONTACT US
Founder
June 18, 2026
For NYC-based fintech, media, and enterprise platforms scaling their machine learning infrastructure, the softmax function is more than just a mathematical equation—it is the critical final layer that turns raw computational data into actionable business intelligence.
Whether you are building Convolutional Neural Networks (CNNs) for image recognition or scaling the attention mechanisms within Large Language Models (LLMs), softmax is the bridge between a model's arbitrary numbers and a valid probability distribution.
While most tutorials focus strictly on the math, this guide explains how the softmax function operates within real production systems.
The softmax function converts a vector of raw, unnormalized numbers (often called "logits") into a valid probability distribution. It ensures that every element in the output vector falls between 0 and 1, and that the sum of all elements equals exactly 1.
The function performs two main operations on an input vector with elements:
Exponentiation: It applies the exponential function () to each raw score. This turns all negative numbers into positive values and amplifies the differences between larger and smaller scores.
Normalization: It divides each exponentiated score by the sum of all exponentiated scores.
For a given element in a vector of scores , the softmax function is calculated as:
: The raw score (logit) of the specific class you are calculating the probability for.
: The exponential of that score.
: The sum of exponentials for all possible classes in the output vector.
Choosing the right activation function is a common architectural hurdle. In enterprise AI pipelines, combining these functions correctly dictates your model's accuracy:
Softmax: Preferred for multi-class classification (mutually exclusive classes) where an item can only belong to one distinct category. It normalizes outputs across multiple classes to sum to 1.
Sigmoid: Typically used for binary classification or multi-label tasks. It outputs independent probabilities between 0 and 1, without guaranteeing the sum equals 1.
ReLU (Rectified Linear Unit): While softmax handles the final output layer, ReLU is commonly used in hidden layers to introduce non-linearity and allow for efficient, rapid learning without the vanishing gradient problem.
Imagine a neural network predicting transaction categories for a banking application, outputting raw logits for three classes: Legitimate, Flagged, and Fraudulent.
Logits:
Exponentiation:
Sum of Exponentials:
Softmax Calculation:
The model confidently assigns a 71% probability to Legitimate, allowing your automated systems to process the transaction while routing borderline cases for human review.
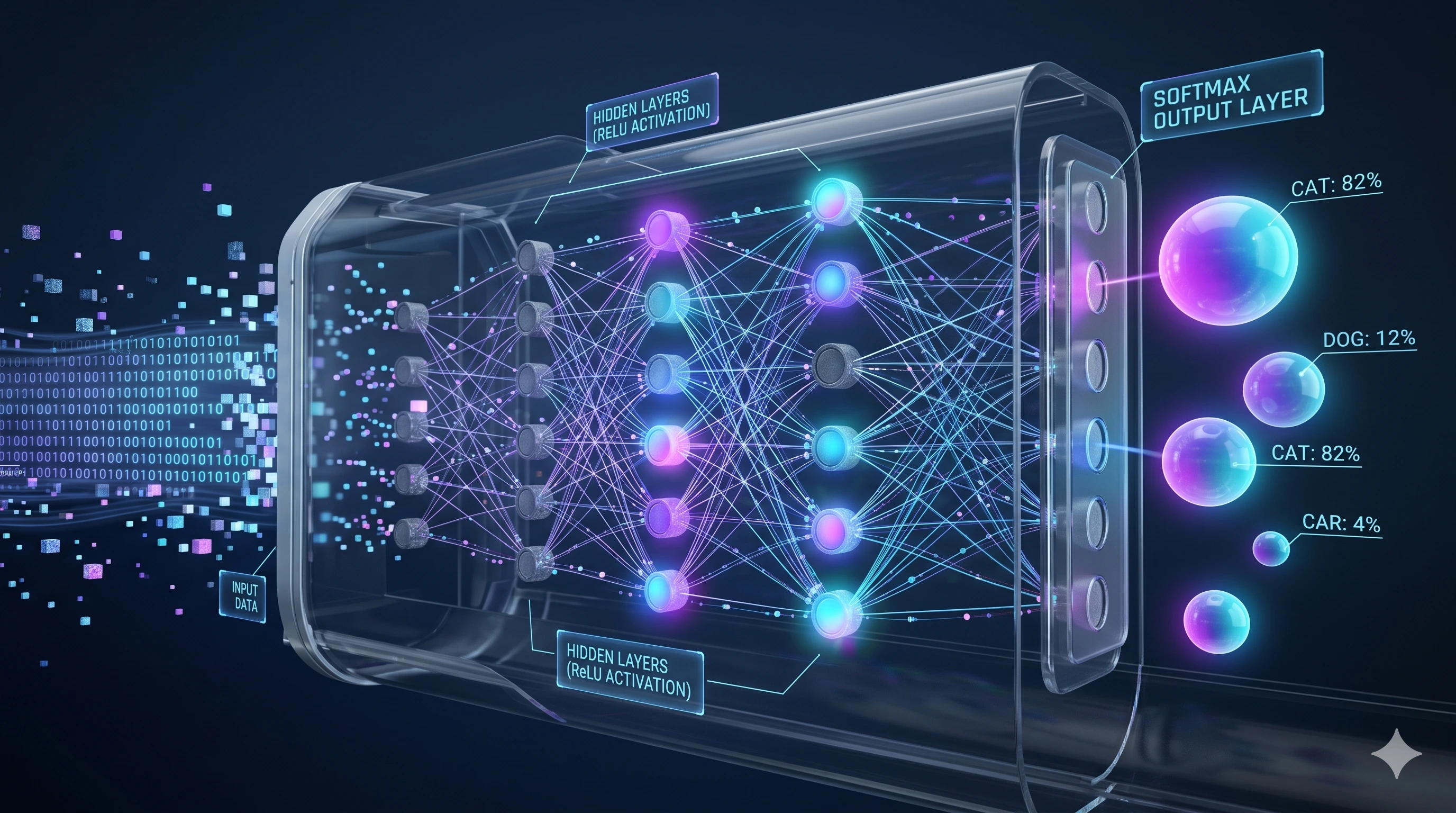
A visual representation of data flowing through hidden layers to generate raw logits, followed by a final Softmax activation layer that normalizes the outputs into a mutually exclusive probability distribution.
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Activation
from tensorflow.keras.optimizers import SGD
# Define an enterprise-grade CNN model
model = Sequential()
# Hidden layers utilize ReLU for efficient learning
model.add(Conv2D(32, (3, 3), input_shape=(64, 64, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(128))
model.add(Activation('relu'))
# The Output layer utilizes Softmax for a valid probability distribution
model.add(Dense(3)) # E.g., 3 classes: Legitimate, Flagged, Fraudulent
model.add(Activation('softmax'))
# Compile utilizing categorical cross-entropy loss
model.compile(loss='categorical_crossentropy', optimizer=SGD(), metrics=['accuracy'])Universal Equations approaches machine learning infrastructure through:
Architectural Rigor: Deploying correct-by-design CNNs and LLMs tailored to your data footprint.
Operational Visibility: Ensuring complete observability across Databricks pipelines and Kafka event streams.
Seamless Interaction: Bridging the gap between raw data and human-centric dashboards.