Search
Categories
Recent Posts
-
operating-systems
Enterprise Application Integration with Oracle SOA Suite -

software-development
Our Flutter and React Native Mobile App Development Agency -

data-science
What is Databricks Dolly LLM?
Open Source: What is Kafka Used for?
Apache Kafka (Not to be confused with Franz Kafka) is an open-source distributed event streaming platform used for high-performance data pipelines, streaming analytics, and other use cases.
- By Mensah Alkebu-Lan
- 28 September 2022
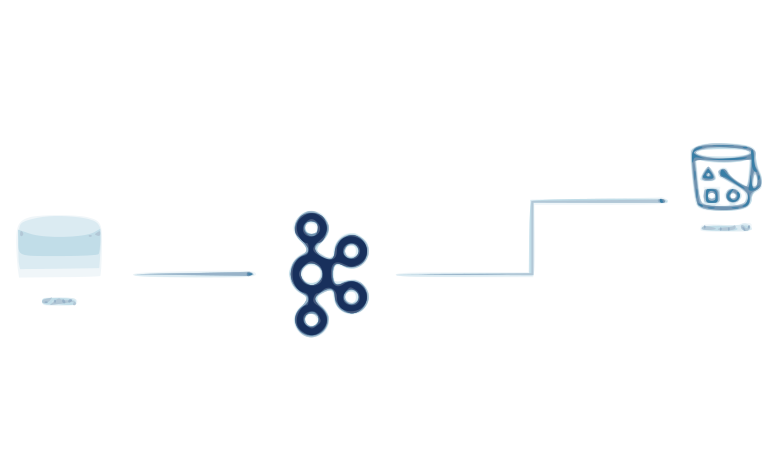
Table of Contents
Introduction
Today, over 80% of Fortune 100 companies use Kafka. But what is it, and what is it used for?
Some of its most common use cases are website activity tracking, stream processing, log aggregation, and event sourcing. Traditionally, each one of these use cases is handled by a different technology. Knowing this, I think it’s much easier to compartmentalize an explanation of what it is and why so many companies use Kafka.
What is Kafka
Apache Kafka (Not to be confused with Franz Kafka) is an open-source distributed event streaming platform used for high-performance data pipelines, streaming analytics, and other use cases. It is a distributed data store optimized for ingesting and processing real-time streaming data. It takes streaming data and records exactly what happened and when.
It has become the backbone of many modern application architectures. For example, Kafka enables moving from actor to channel-centric application development models.
Because of its partitioned log model, records can be distributed across multiple servers. The technology supports both queuing and publish-subscribe messaging models. This gives you flexibility when trying to scale your infrastructure to multiple consumers.
A queuing messaging model will limit the number of consumers processing a record to one, while a publish-subscribe model can publish to all consumers. It can publish and subscribe to, store, process, and publish and subscribe to streams of records.
It is a technology that comes loaded with very helpful features. For example, you can store data streams safely in a distributed, durable, fault-tolerant cluster.
It is known for its high throughput. It is known for its high scalability. In fact, Kafka clusters can be scaled up to a thousand Kafka brokers.
Let’s dig a little into the way Kafka works. It consists of a storage layer and a compute layer that combines efficient, real-time data ingestion, streaming data pipelines, and storage across distributed systems.
It provides durable storage with an abstraction of a durable commit log commonly found in distributed databases. There is the Kafka Streams API – a powerful, lightweight library allowing for on-the-fly processing, letting you aggregate, create windowing parameters, perform joins of data within a stream, and other use cases.
Taking everything in its totality, you begin to get a sense of how powerful this technology is. There is no wonder this project is one of the five most active projects of the Apache Software Foundation.
There are a number of companies offering their own fully managed Apache Kafka service. A few worth noting are Confluent and Amazon Web Services (AWS). These services enable customers to populate data lakes and other data management needs.
What is Kafka Used for?
Apache Kafka is commonly used to build real-time streaming pipelines and applications. A data pipeline reliably processes and moves data from one system to another.
It is used for stream processing. For example, a streaming application consumes streams of data. Stream processing includes operations like filters, joins, maps, and aggregations.
It is also used for streaming ETL. For example, it has a component called Kafka Connect source and sink connectors to consume and produce data from/to any other application, database, or API.
References
- Apache Kafka. Accessed 26 September 2022.
- “What is Kafka?” Confluent. Accessed 26 September 2022.
- guide, step. “What is Apache Kafka?” AWS. Accessed 26 September 2022.
- “What is Apache Kafka?” Google Cloud. Accessed 28 September 2022.
- “Apache Kafka as a service optimized for developers.” Heroku. Accessed 28 September 2022.
- “Apache Kafka Use Cases.” Apache Kafka. Accessed 28 September 2022.
programming language
What is it about the Scala Programming Language?java code
Breaking the Scala Language Barrier